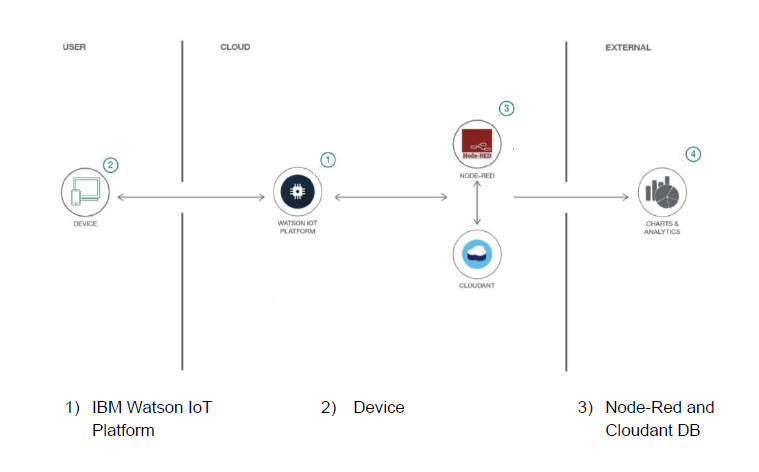
Its been quite some time since I last wrote a blog post, and here I am back at it again! I’m going to forgive myself for that, because after all, its my first time in Europe and things had to settle down! Loving it at trivago!
We are off to an adventure here to select a tool that would best suit the need for a static code analysis tool to be used for validating the code quality of the project that I am currently working on. At the end of it all, we need a tool that compliments Kotlin and ReactJS with Typescript. I have gone with the Weighted Sum Model to rank the tools according to the selected criteria in order to arrive at a result (Power of proof matters :)). So let’s get started!!
Points Considered:
Here’s a list of requirements that I considered as the influence factors in the selection of this static analysis tool.
- Ability to analyse the code quality of Kotlin, React JS and its Typescript files.
- Ability to add rules on demand.
- Active support.
- Support for open source tools and linters.
- Integration with coverage reporting tools.
- Slack integration.
- Jira integration.
- Visual representation.
- Pricing/Free Open source
So here’s the list of contenders going at it and I have chosen to go with the “most known” static code analysis tools out there in the market.
For Kotlin, detekt and ktlint have been evaluated along with the possibilities of providing a better visual experience on the results.
Sonarqube:
A powerful static analysis tool that is also open source. Supports over 26 languages and is capable of not just finding bugs in the code, but also coding rules, test coverage, duplications, API documentation, complexity and much more visually represented through a single dashboard. It also provides moment in time snapshot of the code quality as well as the trends of lagging or leading. The default profiles for specific languages could be customised to add new rules and to remove rules that may not suit the flow of a project. There’s also a comprehensive set of metrics that could be used in tracking the quality of the code. It can also be integrated into Slack, Jacoco and Jira, providing a complete coverage on the development life cycle. Provides active support through its GitHub page and community forum.
| Criteria | Weight | Points | Score |
|---|---|---|---|
| Ability to analyse the code quality of Kotlin, React JS and its Typescript files | 30 | 30 | 30 |
| Ability to add rules on demand | 15 | 15 | 15 |
| Support for open source tools and linters | 10 | 10 | 10 |
| Visual representation | 10 | 8 | 8 |
| Pricing/Free Open source | 9 | 9 | 9 |
| Active support | 8 | 7 | 7 |
| Integration with coverage reporting tools | 6 | 6 | 6 |
| Slack integration | 6 | 6 | 6 |
| Jira integration | 6 | 6 | 6 |
| Total | 97 | ||

97 is a score to beat! let’s see what the others have in store for us!
Code Climate:
A popular code quality tool that identifies potential code errors, security vulnerabilities and provides quantitative and qualitative metrics tracking progress over code based trends. Provides an effective user interface that makes the provided figures and charts easier to understand. Test coverage and maintainability are graded from A to F based on various measures and percentages. There have been instances logged where lots of false positives are shown when the analysis is run for the 1st time, making it not-so-accurate. The metrics applicable are also related to complexity and duplicated code. It can also report code coverage in a comprehensive form of per-file. It also provides integration with Slack and Jira, though issues have been reported on its compatibility with Jacoco. Support is limited as it is provided as requests through their website.
| Criteria | Weight | Score | Comments |
|---|---|---|---|
| Ability to analyse the code quality of Kotlin, React JS and its Typescript files | 30 | 30 | |
| Ability to add rules on demand | 15 | 10 | Checks, plugins and patterns can be added or removed through a yml or json config file. |
| Support for open source tools and linters | 10 | 10 | css, scss, sass etc. available. |
| Visual representation | 10 | 8 | |
| Pricing/Free Open source | 9 | 0 | Paid/Enterprise versions available. |
| Active support | 8 | 3 | Support available through a request form in the website. |
| Integration with coverage reporting tools | 6 | 4 | Coverage tools of popular languages are available. Issues raised over functionality with Jacoco. |
| Slack integration | 6 | 6 | 6 |
| Jira integration | 6 | 6 | 6 |
| Total | 77 | ||
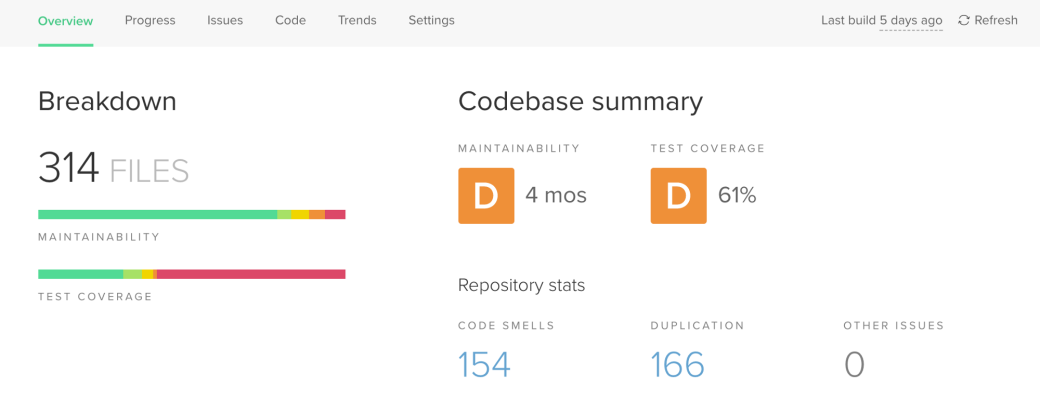
77 isn’t bad. May be the next one will do better!
Codebeat:
A code quality tool that grades the projects similar to Code Climate, but using a 4.0 scale system instead of A-F. Provides a comprehensive user interface that is smooth to use. Tool happens to be more accurate than Code Climate as it is even capable of differentiating similar code to identical code. It also contains a section where it lists down the top 5 issues that affects the code quality in a project. Main drawback for the tool comes from its inability to allow adding of more plugins or rules, leaving the users to stick to the default provided ones. Comes in free for public repositories and paid version for private repositories (Cheaper than Code Climate). Supports integration with Slack and Jira though there it does not accept the output files from Jacoco. Support is available through an online forum though it doesn’t seem to be active.
| Criteria | Weight | Score | Comments |
|---|---|---|---|
| Ability to analyse the code quality of Kotlin, React JS and its Typescript files | 30 | 30 | |
| Ability to add rules on demand | 15 | 0 | Works with default rules. |
| Support for open source tools and linters | 10 | 0 | Doesn’t provide any linters for CSS, SCSS etc. |
| Visual representation | 10 | 8 | |
| Pricing/Free Open source | 9 | 3 | Free only for public repositories. |
| Active support | 8 | 4 | Online forum available but not actively responded. |
| Integration with coverage reporting tools | 6 | 3 | Doesn’t support integration with Jacoco |
| Slack integration | 6 | 6 | |
| Jira integration | 6 | 6 | |
| Total | 60 | ||
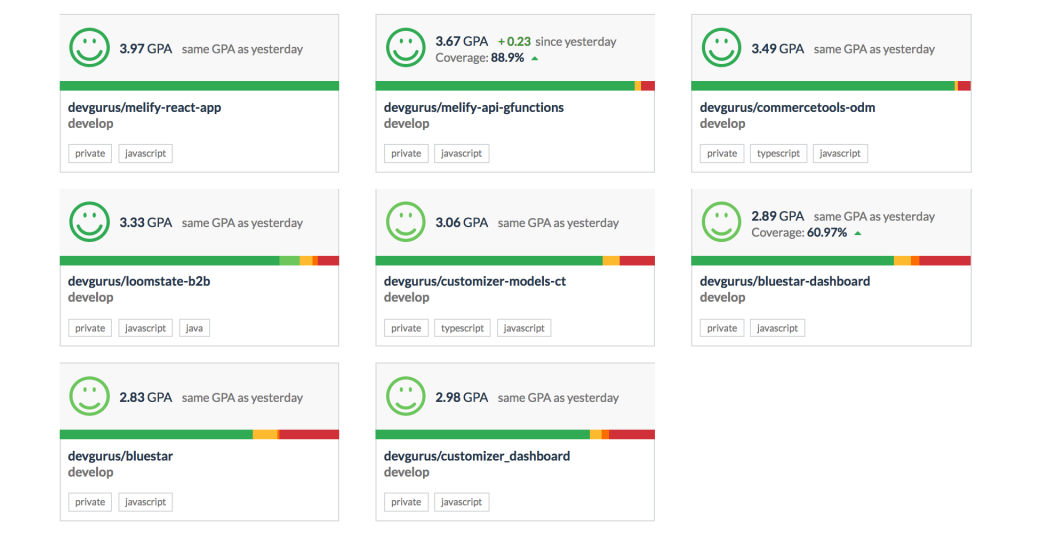
Expected much better from this one, still 60 is a good score!
Codacy:
The last tool to be considered, having a great user interface that is clean and easy on the eyes. Contains a popular user base with companies such as Adobe and Paypal. Provides more metrics compared to Code Client and Codebeat, in the form of code complexity, compatibility, error-prone, security etc. Allows defining goals per file or category and helps providing steps to tackle the issues and meet the goals. Capability to measure code quality for Javascript seems to be lesser compared to other tools. Similar to Codebeat, this also provides a free version for public repositories while different paid plans are provided for private repositories. Integration with Slack, Jacoco and Jira are available. Support is available through requests submitted through the website.
| Criteria | Weight | Score | Comments |
|---|---|---|---|
| Ability to analyse the code quality of Kotlin, React JS and its Typescript files | 30 | 30 | |
| Ability to add rules on demand | 15 | 10 | Allows adding custom extensions and patterns. |
| Support for open source tools and linters | 10 | 10 | Community linters are available |
| Visual representation | 10 | 10 | |
| Pricing/Free Open source | 9 | 3 | Free only for public repositories. |
| Active support | 8 | 3 | Requests submitted online. |
| Integration with coverage reporting tools | 6 | 6 | Doesn’t support integration with Jacoco |
| Slack integration | 6 | 6 | |
| Jira integration | 6 | 6 | |
| Total | 81 | ||
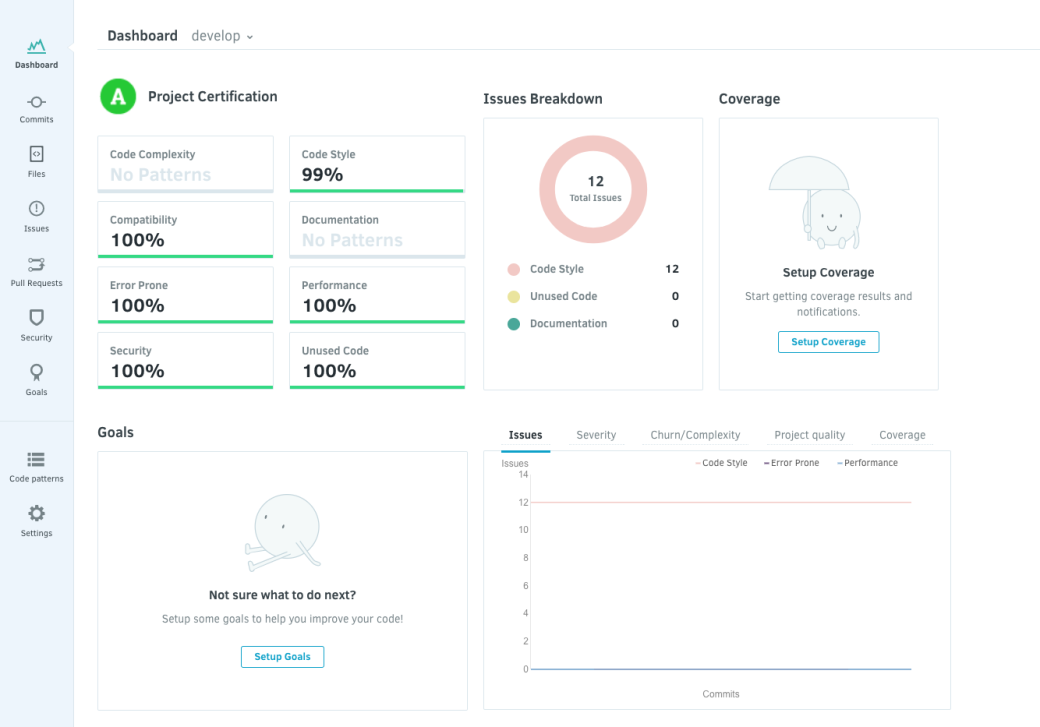
81 was a close call! but we know who stood out!
Based on the rankings resulting from the weighted sum model, Sonarqube seems to be the best option having configurable quality profiles, risk based views, comprehensive reports, custom rules, community support and a downloadable free version that we can setup ourselves.
Static analysis plan for Kotlin:
ktlint and detekt are two of the most popular static analysis tools for Kotlin.
- Provides no configuration options, as it enforces the official code style from kotlinlang.org and Android Kotlin Style Guide.
- Contains a built in formatter.
- Provides command line interface reports or in XML format.
- More of a CheckStyle for Kotlin, and we still need to have Lint for all other checks.
- Highly configurable with custom rules.
- Contains checks for more code smells compared to ktlint.
- Analysis can be run both at build.gradle file level and command line interface level.
- Allows to add more extensions.
detekt contains the edge over ktlint having the capability to find more code smells, is updated quite often and contains lots of configuration options. detekt could also be integrated to Sonarqube with https://github.com/arturbosch/sonar-kotlin. This allows the configurations to be done through sonarqube user interface and provides the reports in an easily readble format through the sonarqube dashboard itself.
In conclusion, Sonarqube is what I’m going ahead, with detekt, for a comprehensive visual representation of the issues and for providing more configuration options (What’s more, both happen to be free! 😀 ).
Aaand so that brings us to a close! Oh on another note, life in Europe has been quite a change, especially for someone who couldn’t even make tea back at home! But then again, here I am making biriyanis for Muslim friends ^_^